Support Research with Enriched Cancer Registry Data
Our overarching goal is to develop and test the algorithms and methods that can be used to augment and enrich SEER registry data with high-quality population-based biospecimen data in the form of digital pathology and correlated quantitative pathomics feature sets to advance the development of reliable, reproducible computational biomarkers to support improved prognostic accuracy and patient stratification capabilities in precision medicine.
To achieve this, we have created and linked a well-curated test repository of high-quality, high-resolution, digitized pathology images and correlated data (devoid of PHI) for a subset of those patients whose data is being collected routinely by the national tumor registries. These images are systematically processed to extract objective computational features, and automated machine-learning classifications. This data and correlated images are being used to establish and project store of searchable archive of images and features, for each of the specimens, which is linked with a limited data set obtained from the New Jersey State Cancer Registry (NJSCR): thus, providing researchers the ability to identify, retrieve and study cohorts exhibiting specific clinical or imaging phenotypes of interest.
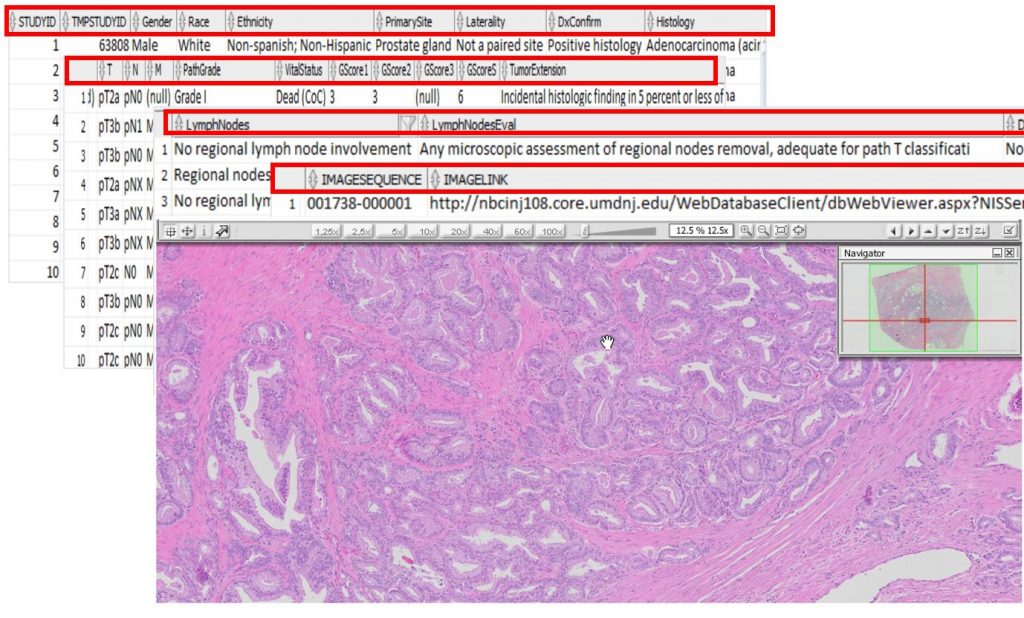
Figure: Supplementing Cancer Registry Data with pathology whole slide scans
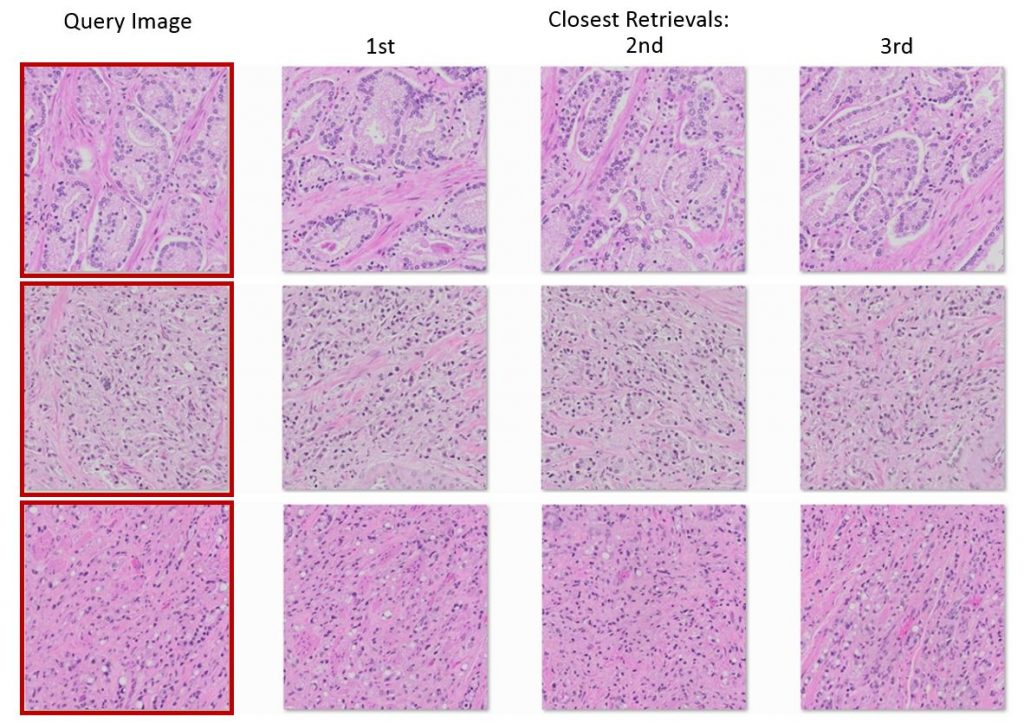
Figure: Texture based image retrieval